Architecture of TypePal
Synopsis
Architectural overview of TypePal
Description
Type checking using TypePal proceeds in the following stages:
- Parse the program to be analyzed using its syntax definition, the result is a parse tree;
- Collect constraints (facts, calculators, and requirements) from the parsed program and build an initial
TModelusing these collected constraints; - Solve the constraints, the result is a validated and further enriched
TModel. This amounts to executing calculators and requirements when the types on which they depend become available. This also involves resolving the semantic links between program parts as introduced by, e.g., import statements.
This approach is very flexible, since each of the stages can be called separately, enabeling a pipeline with user-defined model transformations inbetween.
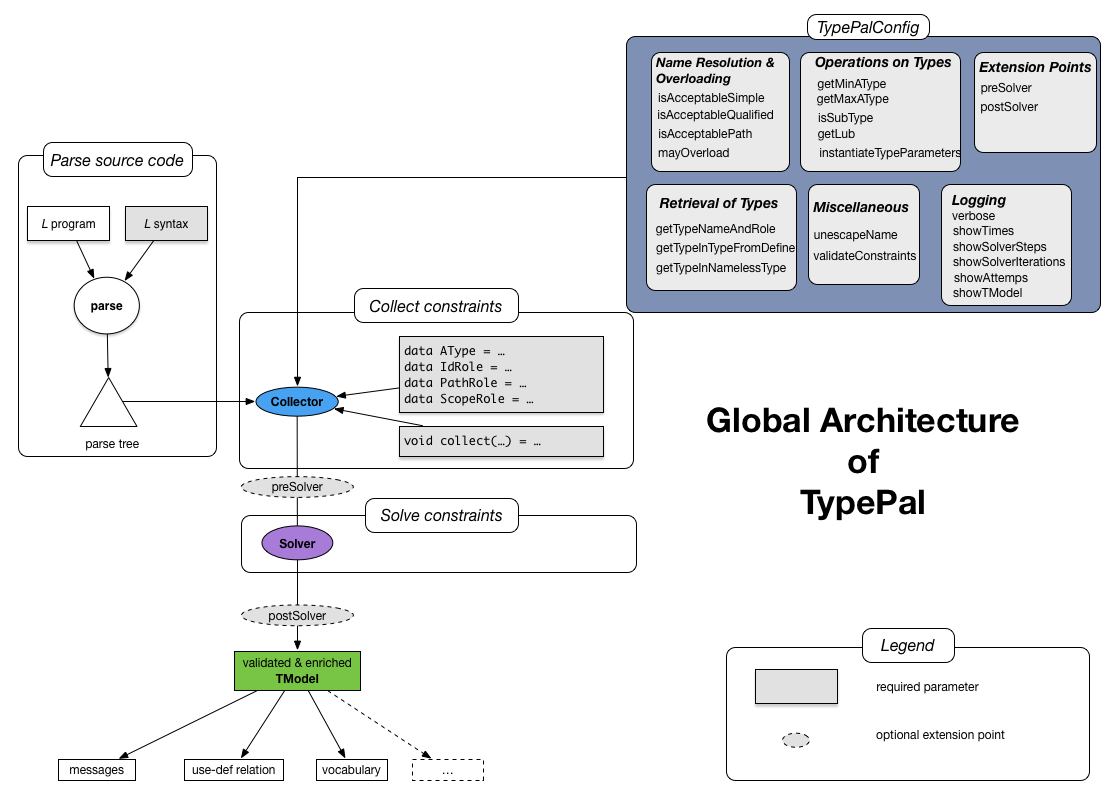
This whole process starts with a syntax for the language we want to analyze (let's call that language L for now). The L syntax is used to parse the L program we want to type check. The result is a parse tree.
Collecting constraints from the resulting parse tree is based on the builder pattern:
first a new Collector is created (using newCollector) and that enables the author of the type checker
to add facts, requirements and calculators to the TModel depending on the specific input program.
The Collector calls user-defined collect functions for each language construct.
This collection process is strictly local and based
on the nested structure of the parse tree and the result is an initial TModel.
After the Collector phase, a TModel is available whose constraints can be solved (or not).
This is done by creating a new Solver (using newSolver) and running it on the given TModel.
TypePal can be configured using a Configuration.