Concepts and Definitions
Synopsis
The concepts and definitions used in TypePal.
Identifier
The syntax of a source language may impose various restrictions on the identifiers that can occur in a program. They amount to including or excluding specific characters for various occurrences of names in the program. One example is the requirement in Java that class names start with an upper case letter. TypePal is agnostic of such conventions and represents each name as a string. Qualified names are also supported and are represented by a list of strings.
Tree
The Rascal data type Tree (REF) is used to represent all parse trees that can be generated for any syntax described in Rascal.
Tree is also a super type of any syntactic construct that may occur in a parse tree.
In TypePal we interchangeably use Tree and the source area (a source location) associated with it to uniquely
identify program parts, definitions, uses and scopes.
Scope
A scope is a region of a program that delimits where definitions of identifier are applicable. An identifier is defined in the scope where it is defined and in all nested subscopes, unless one of these subscopes redefines that same identifier. In that case, the inner definition applies inside that nested scope (and its subscopes). Scopes are identified by the subtree of the parse tree that introduces them such as, for instance, a module, a function declaration or a block. Special rules may apply such as define-before-use or scopes-with-holes.
Scope Graph
The scope graph is one of the the oldest methods to describe the scope of names in a program.
We use a version of scope graphs as described by Kastens & Waite, Name analysis for modern languages: a general solution, SP&E, 2017.
This model uses text ranges in the source text (happily represented by Rascal's loc data type) to identify
and define all aspects of names.
A scope graph provides lookup operations on names that take both syntactic nesting and semantic linking (via paths) into account,
as well as the specific roles of identifiers and paths (described below).
Identifier definition
The definition of an identifier is inside TypePal characterized by a Define:
alias Define = tuple[loc scope, str id, IdRole idRole, loc defined, DefInfo defInfo];
where
scopeis the scope in which the definition occurs;idis the text representation of the identifier;idRoleis the role in which the identifier is defined, see Identifier Role;definedis source code area of the definition;defInfois any additional information associated with this definition, see DefInfo.
Identifier Use
The use of an identifier is characterized by a Use:
data Use
= use(str id, loc occ, loc scope, set[IdRole] idRoles)
| useq(list[str] ids, loc occ, loc scope, set[IdRole] idRoles, set[IdRole] qualifierRoles)
;
where use represents the use of a simple name and useq that of a qualified name.
In the latter case, a list of strings is given; the last string is a simple name in given idRoles and the preceeding strings are its qualifiers in qualifierRoles.
Path
TypePal is based on scope graphs that are not only based on syntactic containment of scopes but can also express semantic
connections between parse trees.
While scopes are strictly determined by the hierarchical structure of a program (i.e., its parse tree),
paths provide an escape from this restriction and define a semantic connection between syntactic
entities that are not hierarchically related and may even be part of different syntax trees.
Connections between syntactic entities are paths labelled with user-defined roles.
Paths are represented by the Rascal datatype PathRole.
An example is the import of a module M into another module N that makes the entities in M known inside N.
Here is an example of a path role to mark an import path between two parse trees.
data PathRole
= importPath()
;
Paths are, amongst others, used in the resolution of qualified names.
Name Resolution
Name resolution is based on the principle: syntactic resolution first, semantic resolution second. This means that we first search for a definition in the current parse tree and only when that fails we follow semantic path to other trees (either in the current tree or in other trees):
- First the current scope in which the name is used is searched for a definition.
- If this fails surrounding scopes are searched.
- If this fails semantic paths in the same parse tree or to other parse trees are searched, such as, for instance, provided by an import statement.
This is illustrated below, where a name occurrence O can be resolved to definitions D1 (syntactic resolution), D2 (semantic resolution) and/or D3 (semantic resolution).
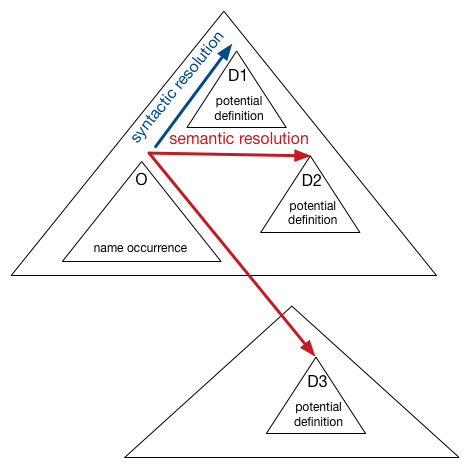
IMPORTANT: Name resolution need not have a unique solution. Therefore the author of a TypePal-based type checker can provide functions to (a) filter valid solutions; (b) determine which identifiers may be overloaded.
Role
Identifiers, scopes and path can play different roles that determine how they will be handled. They are represented by various Rascal datatypes that can be extended by the author of a typechecker.
Identifier Role
Identifier roles are modelled by the data type IdRole.
Here is an example where roles are introduced for constants, variables, formal parameters and functions:
data IdRole
= constantId()
| variableId()
| formalId()
| functionId()
;
When defining an identifier, the specific role of that identifier has to be given, e.g. as constantId().
When using an identifier, the set of acceptables roles has to be given. For instance, an identifier
used in an expression may accept the roles { constantId(), variableId(), formalId() }.
Scope Role
Scope roles are modelled by the data type ScopeRole and are used to distinguish different kinds of scopes.
Later (REF) we will see that this can be used, for instance, to search for the innermost scope with a specific role,
say the innermost function scope. Here is an example that introduces scopes for functions and loops:
data ScopeRole
= functionScope()
| loopScope()
;
Path Role
Path roles are modelled by the data type PathRole:
data PathRole
= importPath()
| extendPath()
;
Types
The type to be associated with names varies widely for different programming languages and has to be provided by the typechecker author.
TypePal provides the data type AType that provides already some built-in constructors:
data AType
= tvar(loc tname) ❶
| atypeList(list[AType] atypes) ❷
| overloadedAType(rel[loc, IdRole, AType] overloads) ❸
| lazyLub(list[AType] atypes) ❹
;
- ❶
tvarrepresents a type variable (used for type inference) and is only used internally. - ❷
atypeListrepresents a list ofATypes and is used both internally in TypePal but can also be used in typechecker definitions. - ❸
overloadedATyperepresents overloaded types. - ❹
lazyLubrepresents a lazily computed LUB of a list of types.
AType that has to be extended with language-specific types.
The typechecker author also has to provide a function to convert AType to string (it is used create readable error messages):
str prettyAType(AType atype);
DefInfo
When defining a name, we usually want to associate information with it such as the type of the defined name.
TypePal provides the data type DefInfo for this purpose:
data DefInfo
= noDefInfo() ❶
| defType(value contrib) ❷
| defTypeCall(list[loc] dependsOn, AType(Solver s) getAType) ❸
| defTypeLub(list[loc] dependsOn, list[loc] defines, list[AType(Solver s)] getATypes) ❹
;
- ❶ No information associated with this definition.
- ❷ Explicitly given AType contribution associated with this definition.
contribcan either be anAType, or aTree. In the latter case, the type of that tree is used (when it becomes available) for the current definition. - ❸ Type of this definition depends on the type of the entities given in
dependsOn, when those are known,getATypecan construct the type of this definition.getATypewill only be called by TypePal during constraint solving. - ❹ Refine a set of definitions by taking their LUB, mostly used for local type inference.
The Solver argument of getAType and getATypes is the current constraint solver being used.
WARNING: noDefInfo may be removed.