Solution Strategies
Synopsis
Strategies to solve problems in various domains using Rascal.
Description
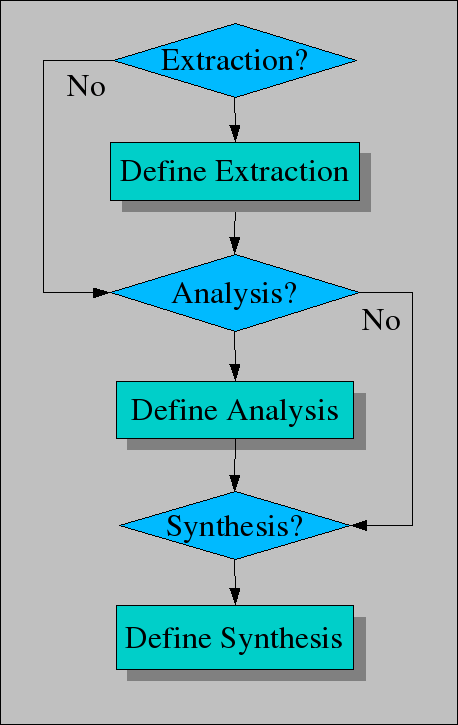
Before you study more complicated examples, it is useful to discuss some general problem solving strategies that are relevant in Rascal's application domain.
To appreciate these general strategies, it is good to keep some specific problem areas in mind:
Documentation generation: extract facts from source code and use them to generate textual documentation. A typical example is generating web-based documentation for legacy languages like Cobol and PL/I.
Metrics calculation: extract facts from source code (and possibly other sources like test runs) and use them to calculate code metrics. Examples are cohesion and coupling of modules and test coverage.
Model extraction: extract facts from source code and use them to build an abstract model of the source code. An example is extracting lock and unlock calls from source code and to build an automaton that guarantees that lock/unlock occurs in pairs along every control flow path.
Model-based code generation: given a high-level model of a software system, described in UML or some other modelling language, transform this model into executable code. UML-to-Java code generation falls in this category.
Source-to-source transformation: large-scale, fully automated, source code transformation with certain objectives like removing deprecated language features, upgrading to newer APIs and the like.
Interactive refactoring: given known code smells a user can interactively indicate how these smells should be removed. The refactoring features in Eclipse and Visual Studio are examples.
With these examples in mind, we can study the overall problem solving workflow as shown in the figure above. It consists of three optional phases:
Is extraction needed to solve the problem, then define the extraction phase, see Extraction.
Is analysis needed, then define the analysis phase, see Analysis.
Is synthesis needed, then define the synthesis phase, see Synthesis.
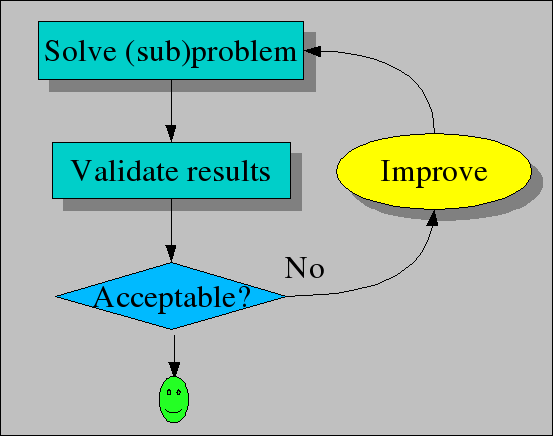
Each phase is subject to a validation and improvement workflow as shown in the second figure. Each individual phase as well as the combination of phases may introduce errors and has thus to be carefully validated. In combination with the detailed strategies for each phase, this forms a complete approach for problem solving and validation using Rascal.
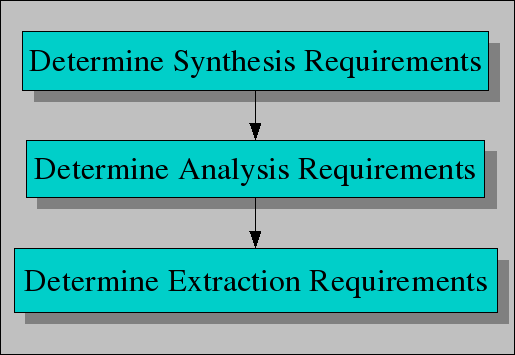
A major question in every problem solving situation is how to determine the requirements for each phase of the solution. For instance, how do we know what to extract from the source code if we do not know what the desired end results of the project are? The standard solution is to use a workflow for requirements gathering that is the inverse of the phases needed to solve the complete problem. This is shown in the third figure and amounts to the phases:
Requirements of the synthesis phase. This amounts to making an inventory of the desired results of the whole project and may include generated source code, abstract models, or visualizations.
Requirements of the analysis phase. Once these results of the synthesis phase are known, it is possible to list the analysis results that are needed to synthesize desired results. Possible results of the analysis phase include type information, structural information of the original source.
Requirements of the extraction phase. As a last step, one can make an inventory of the facts that have to be extracted to form the starting point for the analysis phase. Typical facts include method calls, inheritance relations, control flow graphs, usage patterns of specific library functions or language constructs.
You will have no problem in identifying requirements for each phase when you apply them to a specific example from the list given earlier.
When these requirements have been established, it becomes much easier to actually carry out the project using the three phases of the first figure above.
We will discuss: